大規模な営業・マーケティング組織の現場で、意思決定に必要な情報へ素早くアクセスするには、これまでダッシュボードを何度も切り替え、複数のデータソースを人手で横断する必要があった。AWSの営業・マーケティング・グローバルサービス部門(SMGS)が構築した会話型AIアシスタント「NarrateAI」は、この課題に対して「バッチ処理」と「リアルタイム対話」を分離する設計で応えた。単なるチャットボットではない、業務知能の新たな届け方が示されている。
この記事を一言でいうと
AWS社内の営業組織向けに、Amazon Bedrock AgentCoreを活用したAIアシスタント「NarrateAI」が本番導入された。バッチ処理とリアルタイム対話を分離する二層アーキテクチャと、役割特化型のAIエージェント群によって、大規模組織でのビジネスインテリジェンス提供を実現している。
なぜ話題なのか
営業やマーケティングの現場では、パイプラインの状況、顧客の契約更新時期、過去の商談履歴といった情報が複数システムに散在している。これまでは担当者が各ツールを個別に操作し、必要な情報をかき集める作業が常態化していた。
AWSが自社の営業組織で実装したNarrateAIは、この「情報のサイロ化」に対して、自然言語で問いかけるだけで必要なビジネスインテリジェンスを得られる環境を構築した。特筆すべきは、これがコンセプト実証ではなく、数千人規模の実組織で稼働している点にある。クラウド事業者自身が顧客でもあるという立場から生まれた設計思想には、企業システムとしての実用性を見極める手がかりが詰まっている。
一般読者や企業にどう関係するのか
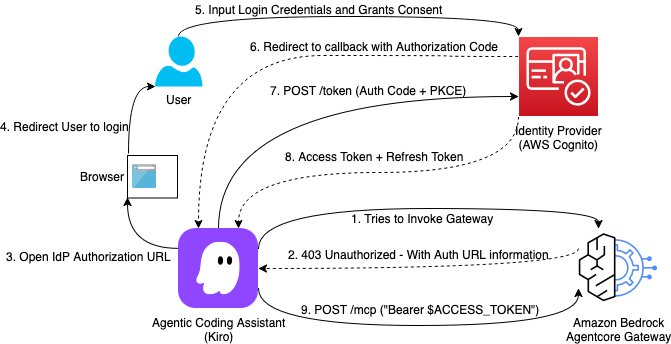
NarrateAIの設計で最も注目すべきは「バッチ処理層」と「リアルタイム対話層」の分離だ。営業データのように日次で更新される大規模データを、深夜のバッチ処理で事前にベクトルデータベースや構造化データストアに展開しておき、対話時にはそれらのインデックス済みデータを参照する。この考え方は、社内データをAIで活用したい多くの日本企業にも直接応用できる。
とりわけ、営業支援システム(SFA)や顧客管理システム(CRM)に蓄積されたデータを、現場の担当者が自然に引き出せるようにする仕組みとして、金融、製造、流通など幅広い業種での導入検討に耐える構造になっている。日本語での自然言語検索や、日本特有の商習慣データへの対応は別途検討が必要だが、アーキテクチャの基本思想は汎用的だ。
AI業界の構造で見ると何が変わるのか
NarrateAIのアーキテクチャは、AIエージェントを「汎用の頭脳」としてではなく「明確な役割を持つ専門機能」として分割している点に構造的な意味がある。具体的には、ユーザーの質問を適切な処理経路に振り分ける「ルーティングエージェント」、生成された回答の正確性を検証する「バリデーションエージェント」、実際のデータ検索と回答生成を行う「応答エージェント」といった機能分割が行われている。
これは、単一の大規模言語モデルにすべてを任せるのではなく、複数のAIエージェントをパイプラインとして組み立てる「複合AIシステム」の実装例だ。Amazon Bedrock AgentCoreのようなマネージドサービス上でこれを実現することで、エージェント間の状態管理やメモリ保持を自前で実装する複雑さを回避している。
クラウド事業者自身がユーザーとなることで、エージェントのオーケストレーション、バッチとリアルタイムの分離、基盤モデルの選択と切り替えといった要素が、単なるベストプラクティスではなく「実運用で検証された設計パターン」として示された意義は大きい。
一次情報から確認できる事実
NarrateAIのアーキテクチャは、以下の要素で構成される。データソース層では、日次バッチでデータレイクから必要な情報を抽出し、ベクトル埋め込みを生成してベクトルデータベースに格納する。この処理により、リアルタイム対話時のレイテンシを低減している。
対話層では、Amazon Bedrock AgentCore上で複数の専用エージェントが連携する。ユーザーからの質問はルーティングエージェントによって適切な処理経路に割り振られ、応答エージェントが必要なデータを取得・生成し、バリデーションエージェントが回答の正確性を検証する。
このシステムはAWS SMGS組織内で実際に稼働しており、営業担当者がパイプライン分析、アカウント情報の取得、ビジネスレビューの準備などに活用している。バックエンドではAmazon Bedrockの基盤モデルを使用し、特定のタスクに応じて最適なモデルを選択できる設計になっている。
関連企業・関連技術
- Amazon Web Services(AWS):Amazon Bedrock AgentCoreを提供。複数エージェントのオーケストレーション、メモリ管理、基盤モデルへのアクセスをマネージドサービスとして提供する
- 基盤モデル提供各社:Anthropic(Claude)、Meta(Llama)など、Bedrockを通じて利用可能なモデルがNarrateAIの基盤を構成する
- ベクトルデータベース:バッチ処理で生成された埋め込みの格納と高速検索を担う。Bedrockのナレッジベース機能と連携
- データレイク・ウェアハウス:営業データの源泉。Amazon Redshift、S3などを通じてデータを集約する
今後の論点
第一に、複数エージェントの協調動作における信頼性担保が挙げられる。バリデーションエージェントが存在するとはいえ、営業判断に関わる情報の誤りをどこまで防げるかは継続的な検証が必要だ。
第二に、日本語を含む多言語対応と、各地域の商習慣に合わせたデータ構造への適応が課題となる。特に日本企業では、商談フェーズの定義や承認フローが欧米とは異なる場合が多く、単純な横展開では対応しきれない。
第三に、基盤モデルの進化とプロプライエタリデータの扱いのバランスも論点だ。モデルが高度化するほど、機密性の高い営業データをどこまでモデルに学習させるか、あるいはRAG(検索拡張生成)の枠組みで閉じるかの判断が重要になる。
第四に、この「バッチ処理+リアルタイム対話」アーキテクチャが、営業領域を超えてサプライチェーン管理や人事、法務などの領域にどこまで展開できるかも注目される。データの更新頻度や検索ニーズが異なる領域ごとに、最適な設計パターンが分岐していく可能性がある。