
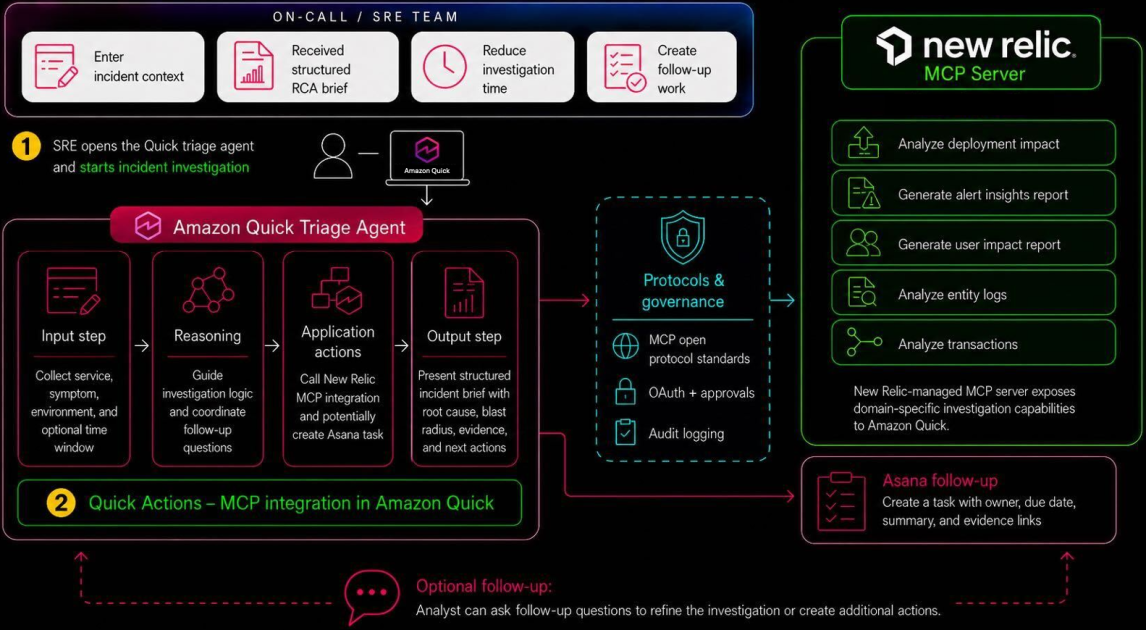
エンジニアリングの現場では、システム障害(インシデント)が発生した際の初動対応が最も神経を使う業務のひとつだ。原因の切り分け、関係者への連絡、対応タスクの作成──これらを手動で回していると、分単位の遅れがサービス全体の信頼を揺るがす。今回、Amazon QとNew Relicの連携によって、この「トリアージ(緊急度・原因の仕分け)」をAIエージェントが自律的に実行する構成が具体的に示された。単なるチャットボットではなく、調査・分析・タスク作成までをワンプロンプトで完結させる設計が、現場の意思決定スピードを根本から変える可能性を持つ。
この記事を一言でいうと
Amazon QがNew Relicの監視データを直接取得・分析し、Asanaのタスク作成までを自律実行するインシデントトリアージの実装例が公開された。エンジニアは自然言語の指示ひとつで、障害の原因分析と対応準備をエージェントに委ねられるようになる。
なぜ話題なのか
システム障害対応は、エンジニアの経験と勘に依存する領域が長く残ってきた。データを集めるだけでも複数のダッシュボードを横断し、ログを引き、チャットで担当者を呼び出す手間がかかる。今回の構成は、MCP(Model Context Protocol)という標準化された接続方式を使って、Amazon Qが直接New RelicのAPIと対話し、リアルタイムの監視データを取得して原因分析にあたる点が新しい。従来のように人がデータを探してAIに渡すのではなく、AI自身が必要な情報を取捨選択して「根拠付きの分析レポート」を生成する。問い合わせからタスク起票までのリードタイムを大幅に短縮できるため、SRE(サイト信頼性エンジニアリング)の現場で注目を集めている。
一般読者や企業にどう関係するのか
企業のIT部門やスタートアップの開発チームにとって、インシデント対応の遅れは直接的に顧客離れや売上損失につながる。たとえばECサイトの決済障害が1時間続けば、その影響額は計り知れない。今回の仕組みは、エンジニアが「いつもより応答速度が遅い原因を調べて、対応タスクを作って」と指示するだけで、AIが自動で異常ホストの特定、エラーログの要約、時系列でのメトリクス比較を実行し、Asana上に関係者がすぐ着手できるタスクを用意する。日本企業においても、24時間365日の運用監視を少人数で回す必要があるSaaS事業者や、大規模な社内システムを抱える製造・金融業にとって、インシデント対応の自動化は運用コストと事業リスクの両面で差別化要因になりうる。
AI業界の構造で見ると何が変わるのか
この事例の構造的な意味は、AIエージェントが「読むだけ」から「動く」段階へ完全に移行したことを示す点にある。Amazon Qは単独のAIアシスタントではなく、MCPを通じて外部サービスと直接対話し、実世界のタスク(タスク管理ツールへの書き込み)まで完遂する。これは、AIがクラウド監視・DevOpsツールチェーン全体の「統合レイヤー」として機能し始めたことを意味する。今後、DatadogやSplunkなど他のオブザーバビリティ(可観測性)製品もMCP対応を進めれば、マルチベンダー環境でのエージェント主導の運用が一般化する。クラウド事業者(AWS、Azure、GCP)とSaaS企業の間で、エージェントがどのデータソースに直接アクセスできるかという「接続性」そのものが次の競争軸になる。
一次情報から確認できる事実
- Amazon QがNew Relic MCP ServerとAsanaのネイティブ連携を用いて、インシデントトリアージを自動化する構成が紹介されている。
- 単一のプロンプトから、Amazon Qがインシデントを調査し、根拠リンク付きのRCA(根本原因分析)ブリーフを作成し、Asana上に追跡可能なタスクを生成するワークフローが完成している。
- New Relic MCP Serverが、Amazon Qによる監視データへの直接アクセスと分析を仲介している。
- この構成は、時間的制約の強いエンジニアリングワークフローへのAI適用例として提示されている。
関連企業・関連技術
- Amazon Web Services(AWS):Amazon Qを提供。企業向け生成AIアシスタントを統合するクラウド基盤。
- New Relic:オブザーバビリティプラットフォーム。MCP Serverを通じて監視データへのアクセスを提供。
- Asana:タスク管理プラットフォーム。インシデント対応タスクの作成・追跡を担う。
- Model Context Protocol(MCP):Anthropicが公開したオープンプロトコル。AIモデルと外部ツール・データソース間の標準化された接続方式。
- SRE/インシデント管理:PagerDuty、Datadog、Splunk On-Callなどの周辺領域も含めた運用自動化市場全体に波及するテーマ。
今後の論点
- MCPの採用が他のオブザーバビリティ製品(Datadog、Grafana、Splunk)にどこまで広がるか。
- インシデントの誤検知やAIの誤分析が起きた場合の責任分担と修正フローが整備されるか。
- エージェントが複数の監視ツールを横断して分析する「マルチソースRCA」が次のステップとして実装されるか。
- 日本国内のクラウド事業者やSaaS企業が、このエージェント主導運用モデルを自社サービスにどの程度取り込むか。

























